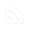
Файл robots.txt
Файл Роботс - запрещает индексацию сайта полностью или файлов и папок (каталогов) расположенных на нем. В нем может содержатся информация о том какое зеркало сайта считать главным, и путь к карте сайта.
 Создав сайт, точнее регнув доменное имя, и пока никакого контента не выложив, я не хотел что бы поисковые роботы шарились по сайту. Для этого я создал в блокноте файл robots.txt, и прописал запрет. Файл получился вот такой:
Создав сайт, точнее регнув доменное имя, и пока никакого контента не выложив, я не хотел что бы поисковые роботы шарились по сайту. Для этого я создал в блокноте файл robots.txt, и прописал запрет. Файл получился вот такой:
User-agent: Yandex
Disallow: / # блокирует доступ ко всему сайту
В чем была ошибка?:
1) Я запретил индексацию только для робота Яндекса.
2) Не прописал директиву host.
Что из этого вышло:
1) Гугл успешно проиндексировал несколько страниц. И когда я изменил кое-какие названия файлов и папок, они продолжали висеть в индексе, а при заходе на них, выдавали 404 ошибку.
2) Яндекс начал индексацию зеркала сайта. Дело в том что, с недавних пор сайты на народе доступны по двум адресам - narod.ru и narod2.ru
Видимо дело было так: Яндекс просканировал домен - zarabotok-na-site.narod2.ru (Видимо через Метрику). Увидел ссылки на запрешенный к индексации сайт на этом успокоился. Но эту одну страницу добавил в индекс. Гугл промониторил выдачу Яндекса, зашел на этот сайт, и уже по ссылкам перешел на zarabotok-na-site.narod.ru.
Заметил это я сегодня, когда решил открыть путь поисковым роботам. Файл роботс естественно переписал. Получилось вот так:
# robots.txt для Яндекса
User-agent: Yandex
Disallow: /speller/# запрещена индексация папки
Disallow: /download/
Disallow: /inc/
Disallow: /statistika.htm # запрещена индексация файла
Host: zarabotok-na-site.narod.ru # главное зеркало
# robots.txt для других роботов
User-agent: *
Disallow: /speller/
Disallow: /download/
Disallow: /inc/
Disallow: /statistika.htm
Индексация полностью разрешена, кроме служебных страниц и каталогов
Что бы грамотно составить файл robots.txt пользуйтесь помощью вебмастера и вот этим сайтом - robotstxt.org.ru. Где все подробно описано и мельчайше разжевано, на примерах.